![[AI] 자연어 처리 - 단어의 표현(2)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2F06KU6%2FbtrJC3ZM3eF%2FiNlhW3LxKg7lR3zoF58Yvk%2Fimg.jpg)
🤔 단어의 의미 파악
단어의 의미를 파악하기 위한 기법들에는 아래 세 가지의 기법이 있습니다.
시소러스 활용 기법
통계 기반 기법
추론 기반 기법
각각의 기법에 대해 알아보는 시간을 가져보도록 하겠습니다.
작성하기에 앞서 [ICT COG Academy] 인공지능 고급(언어)과정을 수강하며 복습을 위해 작성한 글임을 명시합니다.
🔎 시소러스 활용 기법
사람의 경우 단어의 이해를 위하여 "사전"을 활용합니다.
사전에 단어의 의미를 정의해 둔 후 사용합니다.
컴퓨터도 이렇게 할 수 있지 않을까? 라고 생각하여 시소러스 활용 기법이 생겨났습니다.
시소러스란 유의어 사전, 어휘 분류 사전입니다.
즉 뜻이 같은 단어(동의어), 뜻이 비슷한 단어(유의어)가 한 그룹으로 분류되어 있는 사전입니다.
car = auto automobile machine motorcar ...
단어들을 의미의 상/하위 관계에 따라 그래프로 표현합니다.
모든 단어에 대한 유의어 집합을 만든 후 단어들의 관계를 그래프로 표현하여 단어 사이의 연결을 정의합니다.
단어의 네트워크를 이용하여 컴퓨터에게 단어 사이의 관계를 주입합니다.
그래프는 아래와 같습니다.

시소러스 활용 기법의 문제점은 시대 변화에 대응하기 어렵다는 것입니다.
언어는 변하기 때문에 사람이 꾸준히 갱신, 관리해야 합니다.
또한 시소러스를 만들고 관리하기 위한 고가의 인적비용이 발생합니다.
현존 영어단어의 수만 해도 1,000만개 이상입니다.
WordNet에 등록된 단어는 현재 20만개 이상정도입니다.
WordNet은 시소러스의 대표적인 모델입니다.
마지막으로 단어의 미묘한 차이를 표현할 수 없습니다.
뜻은 비슷하지만 느낌, 활용 형태, 활용 상황이 다른 경우가 매우 많습니다.
이러한 문제를 해결하기 위해 통계 기반 기법, 신경망을 이용한 추론 기반 기법 등이 제안됩니다.
🔎WordNet
WordNet은 프린스턴 대학교 심리학 교수 조지 아미티지 밀러 의 지도 하에 1985년부터 개발됐습니다.
기계번역을 돕기 위한 목적으로 개발되었으며, 동의어집합 , 상위어 , 하위어에 대한 정보가 잘 구축되어 있습니다.
유향 비순환 그래프 (Directed Acyclic Graph, DAG)로 구성되어있습니다.
WordNet의 사용 예시는 아래와 같습니다.


아래의 홈페이지를 통해 WordNet의 자세한 정보를 얻으실 수 있습니다.
https://wordnet.princeton.edu/
WordNet
What is WordNet? Any opinions, findings, and conclusions or recommendations expressed in this material are those of the creators of WordNet and do not necessarily reflect the views of any funding agency or Princeton University. When writing a paper
wordnet.princeton.edu
🔎 통계 기반 기법
통계 기반 기법은 통계를 기반으로 어떤 데이터가 많이 사용되는지 데이터가 어떻게 분포되어 있는지 데이터의 분포에 따라 어떤 연관성과 의미를 갖는지 등의 정보를 추출하여 자연어를 처리하는 기법입니다.
통계를 사용하므로 통계 결과를 계산하기 위한 충분한 크기를 가진 대규모의 텍스트 데이터가 요구됩니다.
통계 기반의 자연어 처리 기법은 말뭉치(Corpus)를 이용합니다.
말뭉치는 자연어 처리에 대한 연구, 애플리케이션의 개발 등을 염두에 두고 수집된 대량의 텍스트 데이터입니다.
분포 가설(Distributional Hypothesis)
단어의 의미는 주변 단어에 의해 형성된다는 가설입니다.
단어 자체에는 별 의미가 없고 그 단어가 사용된 맥락(Context)이 의미를 형성한다는 것입니다.
자연어 처리에 관한 중요한 기법은 대부분 분포가설을 기반으로 합니다.
아래는 분포가설의 예입니다.

분포가설을 기초로 통계적 분석을 하기 위해 먼저 어떤 단어가 몇 번 나오는지 직접 세어 보겠습니다.
그전에 동시발생 행렬의 의미를 알아보겠습니다.
동시발생 행렬이란 주어진 단어의 맥락으로써 동시에 발생하는 단어의 출현빈도를 말합니다.
맥락의 크기를 윈도우라고 하고, 윈도우가 1인 경우 주어진 단어에서 한 단어까지 처리합니다.
"You say goodbye and I say hello."
위와 같은 문장이 있을 때 You의 맥락으로 발생하는 단어는 say 뿐입니다.
즉 동시 발생 행렬은 [0, 1, 0, 0, 0, 0, 0]입니다.

say의 맥락으로 발생하는 단어는 You, goodbye, I, hello로
동시 발생 행렬은 [1, 0, 1, 0, 1, 1, 0]입니다.

조금 더 자세하게 알아보겠습니다.
맥락이란 특정 단어를 중심에 둔 주변 단어를 말합니다.
이때 맥락의 크기를 "윈도우"라고 부릅니다.
"You say goodbye and I say hello."의 문장에서 '윈도우 = 2'라면 "goodbye"는 You, say, and, I를 맥락에 포함시킵니다.

모든 단어의 동시발생 행렬을 나타내면 아래와 같습니다.

동시발생 행렬을 이용하여 단어를 벡터로 표현하였다면 벡터 사이의 유사도를 계산하여 해당 단어간의 유사도, 관련성을 확인 가능합니다.
벡터간 유사도 계산 방법에는 '벡터의 내적', '유클리드 거리', '코사인 유사도'등을 사용하는 것입니다.
단어 벡터 간의 유사도를 나타낼 때는 코사인 유사도를 많이 사용합니다.
코사인 유사도는 두 벡터가 가리키는 방향이 얼마나 비슷한가를 확인합니다.
벡터의 방향이 완전히 같다면 코사인 유사도 1, 완전히 반대라면 -1값을 가집니다.
코사인 유사도를 식으로 나타내면 아래와 같습니다.
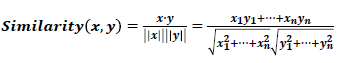
유사도가 높은 순사로 순위를 매겨서 활용할 수 있습니다.
입력 데이터인 말뭋이(Corpus)가 커질 수록 랭킹은 정확해지고 말뭉치가 작을 수록 납득하기 어려운 순위를 보여줍니다.
이런 과정을 거쳐 도출된 각 단어의 유사도 랭킹(순위)에 따라 단어, 문맥(맥락),. 문장에 해당하는 의미를 선택하고 그 결과를 활용하는 것이 통계 기반의 기법입니다.
통계 기반의 기법은 단어의 빈도수를 이용할 경우 문제가 발생할 수 있습니다.
예를 들어 the, car, drive등의 단어가 포함된 말뭉치의 경우 car과 drive가 관련성이 깊은 단어라고 생각할 수 있습니다.
하지만 처리를 해보면 the와 car의 관련성이 더 높은 것으로 계산됩니다.
the와 같은 관사는 내용과 관계없이 가장 많이 사용되는 단어의 하나이므로 최다 빈도수를 가집니다.
아래의 링크를 참고하셔도 좋을것 같습니다.
점별 상호 정보량(Pointwise Mutual Information, PMI)

𝑃(𝑥) : 𝑥가 일어날 확률
𝑃(𝑦) : 𝑦가 일어날 확률
𝑃(𝑥,𝑦) : 𝑥와 y가 동시에 일어날 확률
𝑃𝑀𝐼값이 높을수록 관련성이 높습니다.
말뭉치에 적용하면 𝑃(𝑥): 단어 𝑥가 말뭉치에 등장할 확률이며 𝑃(𝑥,𝑦): 단어 𝑥와 y가 말뭉치에 동시에 등장할 확률을 의미합니다.

동시발생 행렬을 사용하여 다시 정리하면 아래와 같습니다.

𝐶 : 동시발생 행렬
𝐶(𝑥) : 단어𝑥의 등장횟수
𝐶(𝑦) : 단어𝑦의 등장횟수
𝐶(𝑥,𝑦) : 단어 𝑥와y가 동시 발생하는 횟수
𝑁 : 말뭉치에 포함된 단어 수
말뭉치 단어 수가 10,000 개, “the” 1,000 번, “car” 20 번, “drive” 10 번 등장했고, “the”, ”car"의 동시발생 수는 10 회 , “car”, “drive" 의 동시발생 수는 5회라고 가정하겠습니다.
해당 경우의 PMI는 아래와 같이 나타낼 수 있습니다.

"car", "drive"의 관련성이 더 높은 것을 알 수 있습니다.
PMI 문제점 두 단어의 동시발생 횟수가 0 이면 𝑙𝑜𝑔20 = −∞가 됩니다.
문제 해결을 위하여 실제 구현 시에는 양의 상호정보량 (Positive PMI, PPMI) 사용합니다.

PMI / PPMI 모두 말뭉치의 어휘 수 증가에 따라 단어벡터의 차원 수가 증가하게 됩니다.
그래서 차원 감소를 위한 방안이 요구됩니다.
단순한 차원 감소가 아니라 "중요한 정보"는 최대한 유지하면서 줄여야 합니다.
단어 벡터는 주로 원핫 인코딩과 같은 희소백터(=희소행렬)를 사용합니다.
이후 희소벡터에서 중요한 축을 찾아내어 더 적은 차원으로 다시 표현하는 것이 핵심입니다.
다양한 차원 감소 기법 중 단어 처리에 주로 사용되는 것은 특잇값 분해 (Singular Value Decomposition, SVD)입니다.
PTB(Penn Treebank) 데이터 셋도 존재하지만 넘어가도록 하겠습니다.
🔎 추론 기반 기법
추론 기반 기법은 신경망을 이용한 추론을 기반으로 단어의 분산표현을 얻는 기법입니다.
통계 기반 기법과 마찬가지로 분포가설을 기초로 합니다.
통계 기반 기법이 학습 데이터를 한꺼번에 처리하는 것과 다르게 추론 기반 기법은 학습 데이터의 일부를 사용하여 순차적으로 학습합니다.
말뭉치의 어휘 수가 많아 SVD 등 계산량이 큰 작업을 처리하기 어려운 경우에도 학습이 가능합니다.
또한 GPU를 이용한 병렬 계산이 가능해 학습 속도가 향상됩니다.
추론 기반 기법에서의 추론은 주변 단어의 맥락을 사용하여 해당 부분이 들어갈 단어를 추측합니다.

이러한 추론 문제를 반복 수행하여 단어의 출현 패턴을 학습합니다.
신경망에서 단어를 처리할 때 단어를 고정 길이의 벡터로 변환합니다.
벡터의 원소 중 1개만 1이고 나머지는 모두 0인 벡터, 이를 원 핫 벡터(One-Hot-Vector)라고 합니다.
"You say goodbye and I say hello"라는 문장이 있을 때 아래와 같이 나타낼 수 있습니다.



추론 기반 기법을 사용하는 임베딩 모델로 Word2Vec 이 있습니다.
아래의 링크를 참고하시면 좋을 것 같습니다.
https://en.wikipedia.org/wiki/Word2vec
Word2vec - Wikipedia
From Wikipedia, the free encyclopedia Jump to navigation Jump to search Models used to produce word embeddings Word2vec is a technique for natural language processing published in 2013. The word2vec algorithm uses a neural network model to learn word assoc
en.wikipedia.org
CBOW(Continuous Bagof Words) 모델과 skip-gram 모델이 있습니다.
CBOW: 신경망의 입력을 주변 단어들로 구성하고 출력을 타깃 단어로 설정하여 학습된 가중치 데이터를 임베딩 벡터로 활용
skip-gram: 하나의 타깃 단어를 이용하여 주변 단어들을 예측하는 모델 (CBOW 와 반대)
해당 모델의 상세한 훈련 방식은 아래 링크를 참고해주세요.
🔎 CBOW 모델 vs skip-gram 모델
마지막으로 각 모델의 차이점을 알아보고 글을 마무리하겠습니다.
Skip-gram 모델의 경우가 더 좋은 결과를 출력합니다.
Skip-gram 모델은 맥락의 수 만큼 추측하며 손실함수는 각 맥락에서 구한 손실의 총합입니다.
CBOW모델은 타겟 하나의 손실이 발생합니다.
정밀도면에서 skip gram 모델이 우세하다는 것을 알 수 있습니다.
말뭉치가 커질수록 저빈도 단어 , 유추문제 성능에서 skip gram 모델이 CBOW보다 뛰어납니다.
단, 학습 속도는 CBOW 모델이 빠릅니다.
Skip-gram 모델은 맥락의 수 만큼 손실을 구해야 하므로 계산비용이 높아진다는 단점이 있습니다.
아래의 그림으로 한 번에 정리했습니다.
CBOW skip-gram

다음 글에서는 자연어 처리과정 중 워드 임베딩 과정에 대해 알아보겠습니다.
'AI > 자연어 처리' 카테고리의 다른 글
| [AI] 자연어 처리 - 단어의 표현(1) (0) | 2022.08.11 |
|---|---|
| [AI] 자연어 처리 - 전처리와 토큰화(3) (0) | 2022.08.11 |
| [AI] 자연어 처리 - 전처리와 토큰화(3) (0) | 2022.08.06 |
| [AI] 자연어 처리 - 전처리와 토큰화(2) (2) | 2022.08.05 |
| [AI] 자연어 처리 - 전처리와 토큰화(1) (2) | 2022.08.01 |